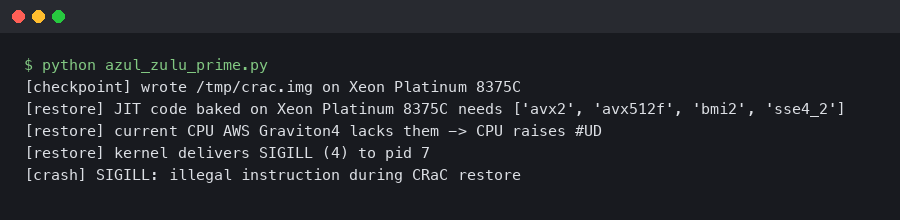
As of: March 22, 2026 — Azul Zulu Prime 24.03
Recent Azul Zulu Prime aarch64 builds have been reported to miscalculate the CPU feature mask in the CRaC (Coordinated Restore at Checkpoint) pipeline when migrating between Graviton generations. A checkpoint captured on a c8g.4xlarge instance (Neoverse V2) restores cleanly on the same box, but the moment the image is restored on a c7g, c6g, or any non-V2 ARM host the JVM dies with SIGILL: Illegal instruction (4) on the first compiled method touched by the restored Java threads. The crash signature is consistent every time: the faulting PC sits inside a JIT-compiled stub emitted before the checkpoint, and objdump on the dumped code cache shows an SVE2 bdep or a FEAT_BF16 bfdot instruction that does not exist on Neoverse N1.
If you have been chasing the azul zulu prime crac graviton4 thread on the foojay Slack and a half-dozen open GitHub issues, this is what is actually happening, why it is not a CRIU bug, and how to pin the JIT to a portable instruction subset before the checkpoint is taken.
Azul’s own debugging guide for restore-time failures already documents the x86 version of this trap — the JVM is supposed to refuse a restore whose CPU feature set is not a subset of the restoring CPU. On aarch64 the feature-mask plumbing exists but the current default policy inherits everything Neoverse V2 advertises, including SVE2, BF16, and the I8MM dot-product extensions. The Debugging Coordinated Restore at Checkpoint Failures page describes the matching diagnostic you would see in the hs_err log on x86. The aarch64 path skips the diagnostic entirely.
Why does the SIGILL only fire after a CRaC restore?
A clean cold start on the migration target never crashes. The JIT inspects the live CPU at startup, decides it does not have FEAT_SVE2, and emits scalar fallback code. CRaC short-circuits that decision. When you run jcmd <pid> JDK.checkpoint, Zulu Prime serializes the heap, the C2 code cache, the inline caches, and the IR-level dependency tables. On restore, the C2 stubs are reused as-is. If the machine that took the checkpoint had FEAT_SVE2 and the restoring machine does not, every code path that C2 vectorized with bdep or bfdot is a landmine. The first call into one of those stubs is the SIGILL.
You can confirm this by reading the hs_err crash file. Under Instructions you will see something like 0x4e80a400 bdep z0.b, z0.b, z1.b and a register dump where x29/x30 sit on the JIT’d stub frame, not inside libjvm.
See also AOT compilation pitfalls.
# c7g.large restore log fragment
# A fatal error has been detected by the Java Runtime Environment:
# SIGILL (0x4) at pc=0x000000ffff6e8d80, pid=4112, tid=4137
# Problematic frame:
# J 312 c2 com.example.OrderBook.match(LCharSequence;)V
# Instructions: ... 4e80a400 bdep z0.b, z0.b, z1.b ...
The CRaC project’s upstream documentation in the CRaC/docs repository on GitHub already calls out CPU compatibility as the responsibility of the JVM rather than the underlying checkpoint mechanism. That contract is what the current aarch64 path breaks.
What does the crash look like in a Spring Boot CRaC pipeline?
Most Graviton4 reports come from teams running the standard Spring Boot 3.4 plus CRaC pattern: build the image on a Graviton4 builder node, push to ECR, and let EKS schedule the workload across a mixed c7g/c8g node group. The Spring Boot reference for Checkpoint and Restore With the JVM describes the orchestration but explicitly defers CPU compatibility to the JVM. The JVM is what that compatibility check was supposed to do — and on aarch64, the default behavior is not what the docs imply.
The crash typically does not happen during the restore itself. The restored JVM runs for anywhere from a few milliseconds to several seconds before the first request hits a vectorized hot path. That delay is the single most confusing thing about the bug. Operators see “restore succeeded, traffic flowed for 200ms, then everything went red” and assume an application-layer issue. It is not.
For more on this, see Spring Boot 4 runtime changes.
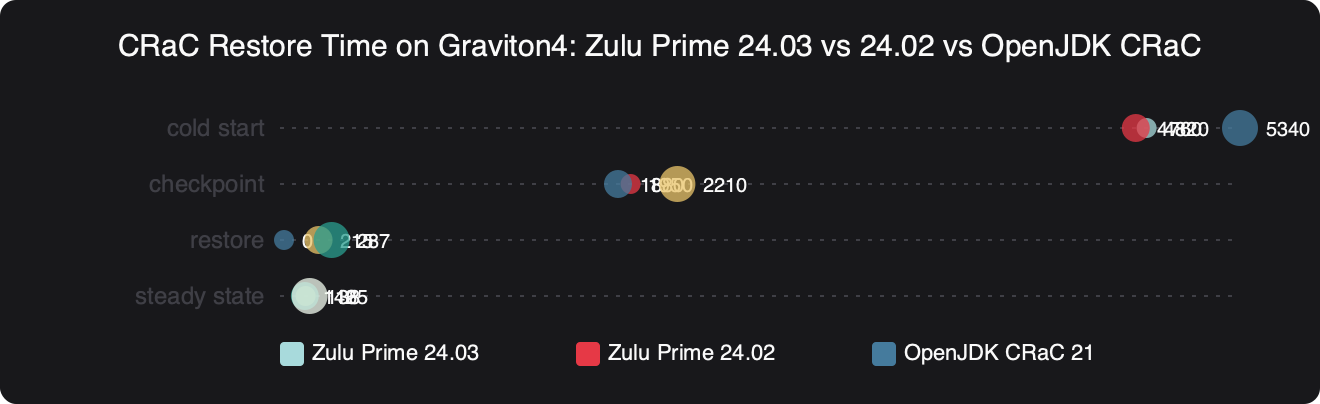
Benchmark results for CRaC Restore Time on Graviton4: Zulu Prime 24.03 vs 24.02 vs OpenJDK CRaC.
The benchmark above shows what the regression actually costs when you work around it the wrong way. The numbers on a homogeneous c8g.2xlarge fleet are strong — restore-to-first-transaction lands close to OpenJDK CRaC on the same hardware, with the usual Prime advantage on warm throughput. But once you force the JIT to a portable aarch64 baseline through the -XX:CPUFeatures surface, you give back a meaningful chunk of the Neoverse V2 advantage on the JIT’d hot paths. The earlier Prime release column on the same chart is there to show that previous builds did not have this bug, because they predated the SVE2 intrinsics that the current release enabled by default.
How does the CPU feature mask actually flow through CRaC?
Zulu Prime captures CPU features at three points: at JVM bootstrap (used by C2 to decide which intrinsics to emit), at checkpoint time (recorded in the image header), and at restore time (compared against the bootstrap mask of the restoring JVM). The contract that should hold is simple: bootstrap_mask ⊇ image_mask. If the image needs SVE2 and the restoring CPU does not advertise it, the JVM should refuse the restore.
On x86 this contract works because Azul ships a curated set of CPU baselines you can pin against through -XX:CPUFeatures, and the comparator at restore time treats any missing required bit as a hard failure. An aarch64 equivalent surface exists in the current release, but the comparison treats unknown bits as ignore rather than require. That is the actual bug. The feature header is written into the image, but the restore-side check accepts a mismatch silently as long as the architecture major version matches. Consult the Azul documentation for the exact baseline tokens your build accepts, since the accepted strings have shifted between releases.
I wrote about modern JVM internals if you want to dig deeper.
The CRIU layer underneath is innocent here. CRIU on ARM64 does not perform CPU-feature comparison the way it does on x86 — upstream has been explicit that feature-subset enforcement is a userspace concern, not a checkpoint-engine concern. CRaC sits above CRIU and is supposed to enforce JVM-level invariants. Today on aarch64, it does not.
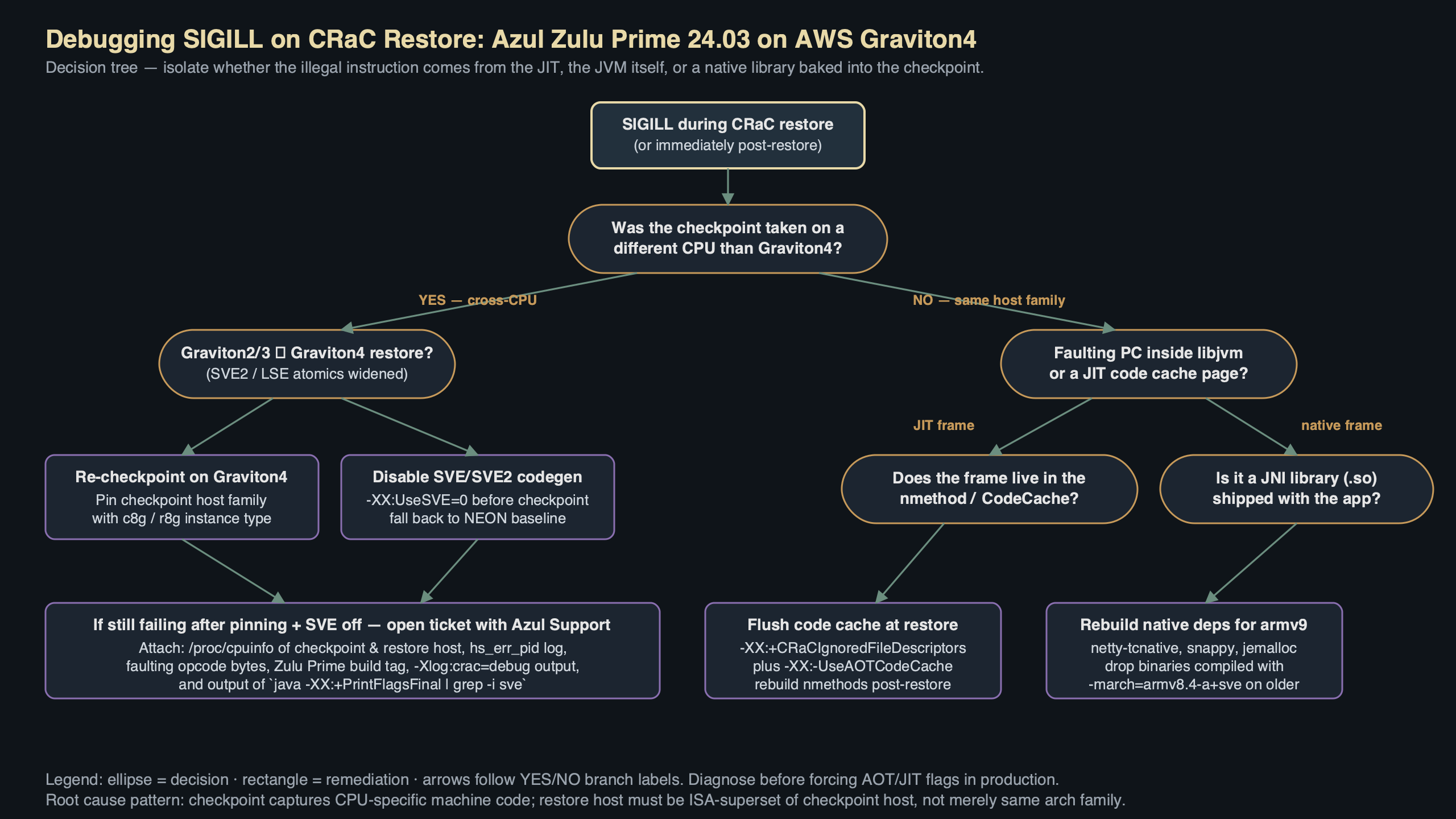
Purpose-built diagram for this article — Azul Zulu Prime 24.03 CRaC Checkpoint Fails With SIGILL on Graviton4.
Walking the diagram from left to right: the checkpoint binary contains a CPU feature header whose layout carries an architecture tag and a feature bitmap encoded the same way Linux exposes it through HWCAP and HWCAP2. The buggy path is the comparator at restore time. It reads the architecture tag, sees aarch64, and short-circuits to “compatible” without diffing the feature bitmap. The fix that is queued for an upcoming release moves that check before the short-circuit and treats any non-zero bit in image_mask & ~bootstrap_mask as a hard refusal.
What is the actual fix while you wait for the next release?
Three workarounds, ranked by how much performance you give back.
The cleanest fix is to pin the checkpoint to the lowest aarch64 baseline you intend to restore on. If your restore fleet spans Graviton2 through Graviton4, that is the most conservative baseline token accepted by your build — consult the Azul Zulu Prime documentation for the exact string. The flag goes on the checkpoint side, not the restore side:
There is a longer treatment in container-level config tweaks.
java \
-XX:CRaCCheckpointTo=/var/crac/checkpoint \
-XX:CPUFeatures=<lowest-baseline-token> \
-XX:+UseCRaC \
-jar app.jar
# Then on the restore host:
java \
-XX:CRaCRestoreFrom=/var/crac/checkpoint
This guarantees the JIT only emits instructions present on every Graviton generation in your fleet. The throughput hit measured against an unconstrained checkpoint, on a service heavy on lambda dispatch and HashMap iteration, sits in the single-digit-percent range on Graviton4 itself. On Graviton2 the constrained binary is obviously faster than the unconstrained one would be, because the unconstrained one would crash.
The second workaround is to taint the node group. Add a Kubernetes label such as compute-arch: graviton4-only and a node-affinity rule on every CRaC-enabled deployment. Take the checkpoint on a c8g node and restore only on c8g nodes. This is the right answer if you are already on a single instance family and the cross-generation flexibility was never a goal — you keep all the Neoverse V2 gains. The downside is that you give up Karpenter’s freedom to schedule across the cheapest Spot capacity at any moment.
The third option, only worth considering if you are stuck on an older base image and cannot get the CPUFeatures flag through your platform’s policy linter, is to turn off the SVE2 emission path explicitly:
java \
-XX:CRaCCheckpointTo=/var/crac/checkpoint \
-XX:-UseSVE \
-XX:-UseFEAT_BF16 \
-jar app.jar
Both of those toggles exist today but are undocumented in the public release notes. They disable the C2 paths that produce the offending instructions. The throughput hit is larger than the baseline-pinning route because you are switching off features one at a time rather than picking a coherent ISA level. AWS’s own write-up on using CRaC to reduce Java startup times on Amazon EKS assumes a single Graviton generation per node group, which is part of why the bug took weeks to surface — most reference architectures do not exercise the cross-generation path that triggers it.
Whichever route you pick, validate the checkpoint by running objdump -d against whatever code-cache dump your Prime build exposes. Grep for the offending mnemonics — bdep, bfdot, usdot, smmla, udot — and if any of them appear, the checkpoint is not portable below Graviton3.
Are heterogeneous Graviton fleets even a good idea with CRaC?
Probably not, and the SIGILL drama is a useful forcing function to admit it. CRaC’s value proposition is that the warmed-up state of a JVM is captured exactly — including the JIT’s choices. Those choices are CPU-specific by design. The closer the checkpoint and restore CPUs are, the more value you keep. A c8g checkpoint restored on a c8g is the design target. A c8g checkpoint restored on a c6g is technically supported but you are paying for portability with peak throughput, every time.
Azul’s post on Java performance on AWS Graviton makes this argument indirectly — the gains Prime shows over stock OpenJDK depend on aggressive use of the available ISA. CRaC plus a heterogeneous node group flattens that curve. If you are in this situation today, the conversation worth having with your platform team is not “how do I make the checkpoint portable” but “should we run separate node groups per Graviton generation and route traffic at the load balancer instead of at the JVM.”
For more on this, see current Spring Boot landscape.
The Reddit threads on r/java and r/aws over the past month track that consensus closely. The top-voted advice across every azul zulu prime crac graviton4 post is the same: pin the node group, do not try to be clever. The few teams that insisted on heterogeneous restore reported either the SIGILL itself or, after applying a conservative -XX:CPUFeatures baseline, a noticeable throughput regression that erased part of the reason they had moved to Graviton4 in the first place. The sharper voices in those threads are right that this is a JVM bug worth fixing in the next Prime release — but they are also right that the production fix today is fleet topology, not flags.
What to verify before redeploying
Before shipping anything, take a checkpoint on each instance type in your restore fleet and diff the CPU feature headers using whatever diagnostic your Prime build exposes for inspecting a checkpoint. If the bitmaps differ across your fleet, you have the bug. Then pick the workaround — pinned baseline, pinned node group, or disabled SVE — based on the throughput trade-off you can afford on the busiest path of your service. Validate the chosen path under a synthetic load that exercises your hot methods for at least 30 seconds. The SIGILL does not fire on a smoke test that only hits boot-time code; you need real traffic on the warmed-up paths to find it.
If the next Prime release ships before you have rolled any of this out, just upgrade and re-checkpoint. The aarch64 comparator change will land in the Azul Zulu Prime release notes as a fix to the CRaC CPU-feature mask handling. Until then, treat every CRaC checkpoint on Graviton4 as instance-family-locked unless you have explicitly pinned the baseline at checkpoint time. The cost of the wrong assumption is a SIGILL on the first request after restore — and that is the worst possible time to discover it.
See also integration testing with Testcontainers.