
Introduction: The Renaissance of Java Background Processing
The landscape of the Java ecosystem is currently undergoing a massive transformation. With the rapid cadence of OpenJDK releases, specifically the long-awaited arrival of JDK 21, developers are finding themselves in a golden era of Java news and innovation. While much of the community buzz focuses on Spring Boot news, Quarkus news, and the exciting developments in Spring AI news, there is a critical component of enterprise architecture that has quietly revolutionized how we handle asynchronous tasks: JobRunr news.
Background processing has always been a thorn in the side of distributed system design. Historically, developers relied on heavy frameworks like Quartz or simple, non-persistent @Scheduled annotations that failed in clustered environments. However, the latest updates in the Java ecosystem news highlight a shift toward distributed, persistent, and developer-friendly job schedulers. JobRunr has emerged as a frontrunner in this space, and with its recent major releases, it has fully embraced the modern capabilities of Java 21 news, particularly Project Loom.
In this comprehensive guide, we will explore the latest advancements in JobRunr, focusing on how it integrates with Java virtual threads news to deliver unparalleled throughput. We will dissect the architecture, provide practical implementation strategies, and discuss how these tools fit into the broader context of Jakarta EE news and Microservices architecture. Whether you are following Java self-taught news or are a seasoned architect tracking Oracle Java news, understanding these patterns is essential for building resilient applications.
Section 1: Core Concepts and the Evolution of Job Scheduling
From Quartz to JobRunr: A Paradigm Shift
To appreciate the significance of current JobRunr news, we must understand the problem it solves. In a microservices environment, firing a long-running task synchronously is a recipe for disaster. It blocks threads, leads to timeouts, and offers poor user experience. Traditional solutions often required complex XML configurations or separate deployment units.
JobRunr simplifies this by allowing you to create background jobs using standard Java 8 lambdas. It analyzes the lambda, serializes it to JSON, and stores it in a database (SQL or NoSQL). This approach aligns perfectly with modern Java SE news trends favoring code-centric configuration over verbose XML.
The Architecture of Distributed Processing
JobRunr operates on a distributed architecture that consists of three main components:
- The Producer: The part of your application (e.g., a REST controller) that enqueues a job.
- The StorageProvider: The database (PostgreSQL, MySQL, MongoDB, Redis, etc.) that acts as the source of truth, ensuring jobs are not lost even if the server crashes.
- The BackgroundJobServer: The worker pool that polls the storage provider, deserializes the job, and executes it.
With the advent of Java 21 news, the BackgroundJobServer has received a significant performance boost. In previous versions of Java, thread pools were limited by the operating system’s thread capabilities. Today, with Java virtual threads news (formerly Project Loom news), JobRunr can theoretically handle hundreds of thousands of concurrent jobs without the context-switching overhead of platform threads.
Basic Configuration
Let’s look at how to set up JobRunr in a modern Spring Boot application. This setup assumes you are tracking Spring news and using Spring Boot 3.x with JDK 17 or 21.
package com.example.jobrunrconfig;
import org.jobrunr.jobs.mappers.JobMapper;
import org.jobrunr.storage.StorageProvider;
import org.jobrunr.storage.sql.common.SqlStorageProviderFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
@Configuration
public class JobRunrConfiguration {
// The StorageProvider is the heart of JobRunr persistence
@Bean
public StorageProvider storageProvider(DataSource dataSource, JobMapper jobMapper) {
// Utilizing the fluent API common in recent Java ecosystem news
StorageProvider storageProvider = SqlStorageProviderFactory.using(dataSource);
storageProvider.setJobMapper(jobMapper);
return storageProvider;
}
// Note: In Spring Boot, simply adding the jobrunr-spring-boot-starter
// often handles this automatically, but explicit config gives control.
}This configuration is minimal but powerful. It leverages the existing DataSource, meaning your jobs live alongside your business data. This transactional integrity is a key talking point in Hibernate news and Java performance news, as it simplifies consistency checks.
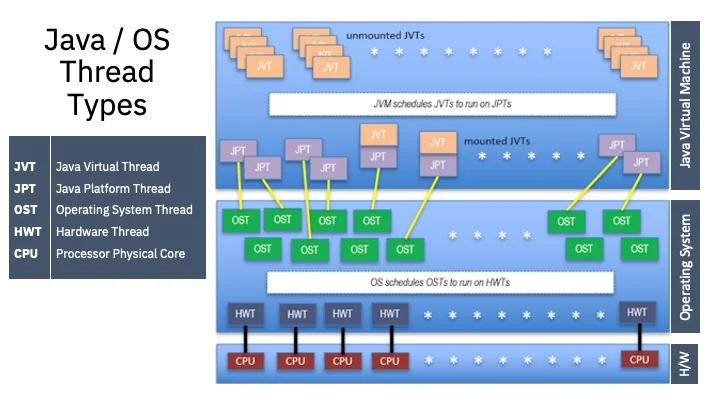
Section 2: Implementation Details and Modern Usage
Fire-and-Forget in the Era of Virtual Threads
The most common use case for JobRunr is the “Fire-and-Forget” pattern. You want to offload a task immediately and return a response to the user. With the latest JobRunr news regarding version 7.x, the API remains consistent, but the underlying execution engine is far more robust.
Here is how you enqueue a job. Notice the use of a lambda expression. This leverages the functional programming aspects popularized in Java 8 news and refined in later versions.
package com.example.service;
import org.jobrunr.scheduling.JobScheduler;
import org.springframework.stereotype.Service;
import java.util.UUID;
@Service
public class NotificationService {
private final JobScheduler jobScheduler;
private final EmailService emailService;
public NotificationService(JobScheduler jobScheduler, EmailService emailService) {
this.jobScheduler = jobScheduler;
this.emailService = emailService;
}
public void sendWelcomePackage(String userId, String email) {
// Enqueueing a background job
// The lambda below is serialized to JSON and stored in the DB
jobScheduler.enqueue(() -> emailService.sendEmail(email, "Welcome!", "Thanks for joining."));
System.out.println("Job enqueued for user: " + userId);
}
// Example of a long-running task potentially involving AI
public void generateEmbeddings(String documentId) {
// Relevant to Spring AI news and LangChain4j news
jobScheduler.enqueue(() -> processVectorEmbeddings(documentId));
}
public void processVectorEmbeddings(String docId) {
// Simulating a heavy AI workload
try {
Thread.sleep(5000);
System.out.println("Embeddings generated for " + docId);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}Recurring Jobs and CRON Expressions
While Spring news often highlights the @Scheduled annotation, it has limitations in clustered environments (executing on every node). JobRunr solves this with persistent recurring jobs. This is vital for tasks like generating daily reports or cleaning up database rows—topics frequently discussed in Java maintenance and wisdom tips news.
package com.example.jobs;
import org.jobrunr.jobs.annotations.Job;
import org.jobrunr.spring.annotations.Recurring;
import org.springframework.stereotype.Component;
@Component
public class ReportingJobs {
// This job will run on only ONE node in the cluster
// CRON expression: At 8:00 AM every day
@Recurring(id = "daily-sales-report", cron = "0 8 * * *")
@Job(name = "Generate Daily Sales Report")
public void generateDailyReport() {
System.out.println("Starting daily report generation...");
// Logic to aggregate data and send PDF
performHeavyAggregation();
}
private void performHeavyAggregation() {
// Simulating database heavy lifting
// This aligns with best practices found in Hibernate ORM news
}
}The @Recurring annotation ensures that even if you spin up 10 instances of your microservice using Kubernetes (a staple in Open Liberty news and Helidon news), the job executes exactly once per interval.
Section 3: Advanced Techniques: Virtual Threads and JobRunr 7
The Game Changer: Project Loom Integration
The most exciting aspect of recent Java ecosystem news is the integration of Virtual Threads (Project Loom). In traditional thread-per-request models, blocking I/O (like calling an external API or querying a database) wastes a platform thread. Since platform threads are expensive resources (1MB stack size usually), this limits scalability.
JobRunr news confirms that version 7+ supports Virtual Threads out of the box. This means your background job server can process I/O-bound jobs with a much smaller memory footprint and higher concurrency. This is a massive leap forward compared to older Java 11 news or Java 17 news paradigms.
To enable this, you need to configure the BackgroundJobServer to use a Virtual Thread executor. Here is how you can achieve this programmatically:
package com.example.config;
import org.jobrunr.server.BackgroundJobServer;
import org.jobrunr.storage.StorageProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.Executors;
@Configuration
public class VirtualThreadConfig {
@Bean
public BackgroundJobServer backgroundJobServer(StorageProvider storageProvider) {
// Creating a virtual thread per task executor
// This requires JDK 21+
var executorService = Executors.newVirtualThreadPerTaskExecutor();
return new BackgroundJobServer(
storageProvider,
executorService
// In JobRunr 7, you can pass the executor or configure the worker pool
// to utilize virtual threads for processing.
);
}
}Note: If you are using Spring Boot 3.2+ with spring.threads.virtual.enabled=true, JobRunr’s Spring starter may automatically pick up the virtual thread task executor, simplifying this further.
Job Filters and AOP
Another advanced feature involves Job Filters. Similar to aspects in AOP (Aspect Oriented Programming), these allow you to intercept job execution. This is useful for logging, setting up MDC contexts for tracing (crucial for Java observability news), or handling multi-tenancy.
package com.example.filters;
import org.jobrunr.jobs.filters.JobServerFilter;
import org.jobrunr.jobs.JobDetails;
public class MdcLoggingFilter implements JobServerFilter {
@Override
public void onProcessing(JobDetails jobDetails) {
// Set MDC context before job runs
// This helps in distributed tracing tools like Zipkin or Jaeger
System.out.println("Processing job: " + jobDetails.getId());
}
@Override
public void onProcessed(JobDetails jobDetails) {
// Clean up MDC context
System.out.println("Finished job: " + jobDetails.getId());
}
// Implement onFailed for error tracking
}Section 4: Best Practices and Optimization
As we digest the influx of Java concurrency news and JVM news, applying best practices ensures our background processing remains stable. Here are critical optimization strategies for JobRunr.
1. Handling Serialization and Evolution
JobRunr serializes your lambda arguments to JSON. A common pitfall discussed in Java wisdom tips news is changing the method signature or the class structure of the arguments after a job has been enqueued but before it is processed. This leads to deserialization errors.
Tip: Always keep your job arguments simple (Primitives, Strings, UUIDs, or simple DTOs). Avoid passing complex entities like Hibernate Proxies. If you must change a DTO, ensure backward compatibility or drain the job queue before deploying.
2. The Null Object Pattern and Error Handling
In the realm of Null Object pattern news and defensive coding, ensure your services handle nulls gracefully. If a job fails, JobRunr has an automatic retry policy (exponential backoff). However, if the error is non-recoverable (e.g., a NullPointerException due to bad data), you should catch it and prevent infinite retries.

@Job(name = "Unreliable External Call", retries = 2)
public void callExternalApi() {
try {
// External call
} catch (FatalException e) {
// Log and swallow exception to stop retry loop
// Or throw a specific exception configured to not retry
}
}3. Database Tuning
Since JobRunr uses your database, heavy job loads can impact your application’s performance. This is a frequent topic in PostgreSQL news and MySQL news. Ensure you have proper indexing on the JobRunr tables. If the load is massive, consider using a separate DataSource or a NoSQL store like Redis or MongoDB for the job storage, keeping your business logic relational database free from locking contention.
4. Monitoring and Dashboard
JobRunr comes with a built-in dashboard. In production, secure this dashboard! Do not expose it publicly. Use Spring Security to put it behind a login. Monitoring your job processing latency is a key metric in Java performance news. If jobs are staying in the “Enqueued” state for too long, you may need to scale out your workers or increase the thread pool size (if not using Virtual Threads).
Conclusion
The convergence of JobRunr news with the broader Java 21 news and Spring Boot news ecosystem represents a significant leap forward for Java developers. We have moved past the days of clunky XML schedulers and fragile in-memory tasks. With tools like JobRunr 7, leveraging Java virtual threads news and Project Loom news, we can build high-throughput, resilient background processing systems that are easy to maintain and monitor.
As you continue your journey—whether you are following Adoptium news, Azul Zulu news, or BellSoft Liberica news—remember that the JVM is becoming more efficient than ever. Integrating these modern tools not only improves application performance but also developer happiness. The ability to write a simple lambda and have it run reliably in a distributed cluster is a testament to the maturity of the current Java landscape.
Stay tuned to InfoQ and other community hubs for more Java ecosystem news. Now is the time to audit your current batch processing and scheduling architecture. If you are still struggling with Quartz or unmanaged threads, the latest JobRunr features offer a compelling path forward.