
In the vast and ever-evolving world of the Java ecosystem, performance is a relentless pursuit. Developers and JVM engineers are in a constant search for optimizations that can shave milliseconds off execution times, reduce CPU cycles, and enhance application responsiveness. While major features like Project Loom’s virtual threads or Project Valhalla’s value types often steal the spotlight, a fundamental, under-the-hood enhancement is on the horizon that promises a significant, widespread performance boost. A forthcoming update to the Java Development Kit (JDK) is set to dramatically accelerate one of the most frequently called methods in the entire platform: String.hashCode(). This seemingly small change has massive implications, directly impacting the performance of core data structures like HashMap and sending positive ripples throughout the entire landscape of Java applications, from monolithic enterprise systems built with Jakarta EE to modern microservices powered by Spring Boot.
The Critical Role of hashCode() in Java Collections
Before diving into the specifics of the optimization, it’s crucial to understand why hashCode() is so fundamental to Java’s performance. The method is the linchpin of all hash-based collections, including HashMap, HashSet, and ConcurrentHashMap. These data structures offer near-constant time complexity, O(1), for basic operations like insertion, deletion, and retrieval, but only if the hash codes of their keys are well-distributed and fast to compute.
The hashCode() and equals() Contract
The Java language specification defines a strict contract between the hashCode() and equals() methods. This contract is a cornerstone of Java wisdom and is essential for any developer, especially those who are self-taught and building their foundational knowledge. The rules are:
- If two objects are equal according to the
equals(Object)method, then calling thehashCode()method on each of the two objects must produce the same integer result. - If two objects are unequal according to the
equals(Object)method, their hash codes are not required to be different. However, producing distinct hash codes for unequal objects can significantly improve the performance of hash tables. - The
hashCode()value for an object should not change during an application’s execution unless the information used inequals()comparisons is modified. This is why using mutable objects as keys in aHashMapis a dangerous practice.
Violating this contract leads to unpredictable behavior in collections, causing elements to be “lost” or lookups to fail. Here is a practical example of a correctly implemented class, a pattern seen across countless applications from Java 8, Java 11, Java 17, to Java 21.
import java.util.Objects;
public final class Employee {
private final long id;
private final String name;
private final String department;
public Employee(long id, String name, String department) {
this.id = id;
this.name = name;
this.department = department;
}
// Getters for id, name, and department
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return id == employee.id &&
Objects.equals(name, employee.name) &&
Objects.equals(department, employee.department);
}
@Override
public int hashCode() {
// Objects.hash() provides a convenient and reliable way
// to compute a hash code from multiple fields.
return Objects.hash(id, name, department);
}
@Override
public String toString() {
return "Employee{" +
"id=" + id +
", name='" + name + '\'' +
", department='" + department + '\'' +
'}';
}
}A Deep Dive into the String hashCode() Optimization
The String class is arguably the most used object in any Java application. It serves as the key in countless HashMap instances—for caching, configuration, request routing, and more. Consequently, the performance of String.hashCode() is a critical factor in overall application speed. The latest OpenJDK news reveals a shift in how this calculation is performed, moving from a traditional, scalar approach to a modern, vectorized implementation.
The Traditional Implementation
For many years, the hashCode() for a String in Java has been calculated using a polynomial hash function. The formula is s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1], where s[i] is the i-th character of the string and n is the length of the string. The number 31 was chosen because it’s an odd prime, and multiplication by 31 can be efficiently performed by a shift and a subtraction: 31 * i == (i << 5) - i. The implementation iterates through each character of the string one by one.
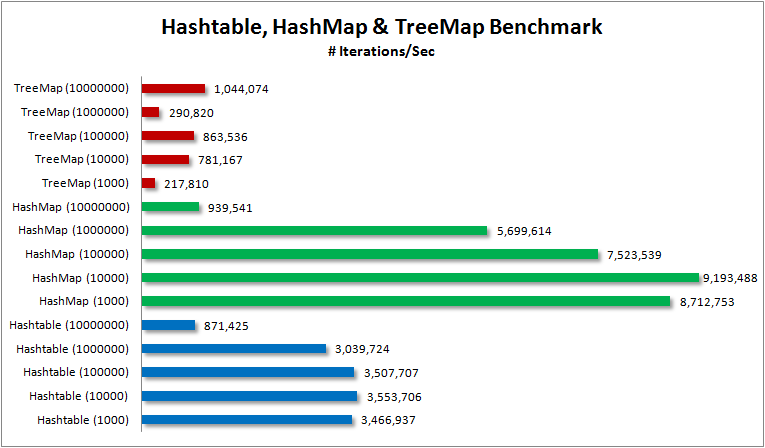
/**
* A simplified demonstration of the classic String hashCode algorithm.
* Note: The actual implementation in the JDK is more optimized and caches the hash code.
*/
public class ClassicStringHasher {
public static int calculateHashCode(String str) {
int h = 0;
int len = str.length();
if (len > 0) {
for (int i = 0; i < len; i++) {
// The core formula: h = 31 * h + val[i]
h = (h << 5) - h + str.charAt(i);
}
}
return h;
}
public static void main(String[] args) {
String key1 = "java-performance-news";
String key2 = "hashcode-optimization-in-jdk";
System.out.println("Hash for '" + key1 + "': " + calculateHashCode(key1));
System.out.println("Hash for '" + key2 + "': " + calculateHashCode(key2));
}
}While effective, this character-by-character approach is inherently sequential and doesn't fully leverage the capabilities of modern CPUs, which excel at performing the same operation on multiple pieces of data simultaneously.
The New Vectorized Approach
The upcoming enhancement leverages SIMD (Single Instruction, Multiple Data) operations. This is a powerful CPU feature that allows a single instruction to process a vector of data (e.g., 8, 16, or even 32 characters) at once. This is closely related to the work being done in Project Panama, which aims to improve the connection between Java code and native code, including access to vector instructions. By processing chunks of the string in parallel, the new algorithm can achieve a massive speedup, especially for longer strings commonly used as keys in JSON payloads, database identifiers, or configuration properties.
While the exact JVM intrinsic is complex, the concept involves loading multiple characters into vector registers and applying the polynomial hash calculation across the entire vector in a single CPU cycle. This is a game-changer for data-intensive applications and a significant piece of Java performance news that will benefit the entire Java ecosystem, from Oracle Java and Adoptium builds to specialized distributions like Azul Zulu, Amazon Corretto, and BellSoft Liberica.
Real-World Impact: Where You'll Feel the Speed
This optimization isn't just an academic exercise; it has tangible benefits across the board. The performance gain will be most noticeable in applications that heavily rely on String-keyed HashMaps.
Accelerating Core Data Structures
Every time you call map.put(key, value), map.get(key), or set.contains(element) where the key or element is a String, the hashCode() method is invoked. A faster hash code calculation directly translates to faster map and set operations. Consider a scenario where an application is parsing a large JSON file and storing its contents in a HashMap. The constant lookup and insertion of string keys will see a direct and measurable improvement.
Let's simulate a simple benchmark to illustrate the potential impact. While a true benchmark requires a tool like JMH (Java Microbenchmark Harness), this example demonstrates the principle.
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
public class HashMapPerformanceDemo {
private static final int NUM_KEYS = 1_000_000;
private static final int LOOKUP_ITERATIONS = 5_000_000;
public static void main(String[] args) {
// 1. Prepare the data
System.out.println("Preparing " + NUM_KEYS + " string keys...");
String[] keys = new String[NUM_KEYS];
Map<String, Integer> dataMap = new HashMap<>(NUM_KEYS);
for (int i = 0; i < NUM_KEYS; i++) {
keys[i] = UUID.randomUUID().toString() + "-" + i;
dataMap.put(keys[i], i);
}
// 2. Warm up the JVM
System.out.println("Warming up the JVM...");
for (int i = 0; i < LOOKUP_ITERATIONS; i++) {
dataMap.get(keys[i % NUM_KEYS]);
}
// 3. Run the benchmark
System.out.println("Running benchmark with " + LOOKUP_ITERATIONS + " lookups...");
long startTime = System.nanoTime();
for (int i = 0; i < LOOKUP_ITERATIONS; i++) {
// This get() call implicitly triggers String.hashCode()
dataMap.get(keys[i % NUM_KEYS]);
}
long endTime = System.nanoTime();
long durationMs = (endTime - startTime) / 1_000_000;
System.out.println("--------------------------------------------------");
System.out.println("Benchmark finished.");
System.out.println("Total lookups: " + LOOKUP_ITERATIONS);
System.out.println("Time taken: " + durationMs + " ms");
System.out.println("With the new JDK optimization, this time is expected to decrease significantly.");
System.out.println("--------------------------------------------------");
}
}Ripple Effects in Frameworks and Libraries
The benefits extend deep into the rich Java ecosystem. This is not just Java SE news; it's also critical Spring news and Hibernate news.
- Spring Framework/Spring Boot: The entire Spring ecosystem relies heavily on string-based identifiers. Bean names, configuration properties (
@Value("${...}")), request mappings (@GetMapping("/path")), and caching mechanisms (@Cacheable) all use strings extensively. Faster hash codes mean faster application startup, faster request processing, and more efficient caching. This also touches on emerging areas like Spring AI, where processing and caching text-based prompts and responses is common. - Hibernate: While primary keys are often numeric, Hibernate's second-level cache frequently uses keys derived from entity names and identifiers, which often involve strings. A faster
hashCode()improves cache lookup performance, reducing database load. - Build Tools (Maven/Gradle): Tools like Maven and Gradle process thousands of dependencies, plugins, and configuration files, all identified by strings (group ID, artifact ID, version). Faster string operations can contribute to slightly quicker build and dependency resolution times. This is welcome Maven news and Gradle news for developers everywhere.
- Testing Frameworks (JUnit/Mockito): Even our testing workflows, covered by JUnit news and Mockito news, will see marginal gains as these frameworks process class names, method names, and string-based arguments during test execution.
Best Practices and Preparing for the Future
The best part about this particular performance improvement is that for most developers, it requires no code changes. Simply by upgrading to the new JDK version when it becomes available, your applications will automatically benefit. However, this news serves as a great reminder of some timeless best practices.
1. Always Keep Your JDK Updated
This is the most critical takeaway. Sticking with older versions like Java 8 or Java 11 means you miss out on years of performance tuning, security patches, and language features. The performance gap between LTS versions is significant, and this String.hashCode() update is a prime example of the "free" performance gains you get by staying current.
2. Understand Your Data Structures
While HashMap is a fantastic default, always choose the right tool for the job. If you have a small, fixed set of string keys, a switch statement on the string (which uses an optimized hash-based lookup behind the scenes) might be even faster. For read-heavy scenarios, consider immutable collections.

3. Look to the Broader Horizon of Java Performance
This optimization is part of a larger trend in Java performance news. The JVM is becoming smarter and more capable with every release. Keep an eye on other transformative projects:
- Project Loom News: Virtual threads are revolutionizing Java concurrency by making it cheap and easy to create millions of threads, simplifying the development of highly scalable, reactive Java applications. This is major Java virtual threads news.
- Project Valhalla News: Aims to bring value types and primitive classes to Java, allowing for flatter, more cache-friendly memory layouts that can eliminate entire classes of memory indirection, boosting performance for data-heavy workloads.
- Project Panama News: As discussed, this project is enhancing the connection to native code, making it easier and safer to leverage native libraries and CPU-specific instructions like SIMD.
Conclusion: A Small Change with a Giant Impact
The upcoming optimization of String.hashCode() is a testament to the Java platform's commitment to continuous improvement. It’s a powerful reminder that performance gains don't always come from sweeping architectural changes but often from meticulous refinement of the core, foundational components. This update will deliver a silent but substantial speed boost to nearly every Java application in existence, from legacy Java EE systems to the latest reactive microservices.
For developers, the key takeaway is clear: stay informed and keep your tools sharp. By adopting the latest JDK releases, you not only gain access to new language features but also inherit a wealth of performance optimizations that make your applications faster, more efficient, and more scalable. This is more than just JVM news; it's a direct enhancement to the productivity and success of every Java developer.