Introduction
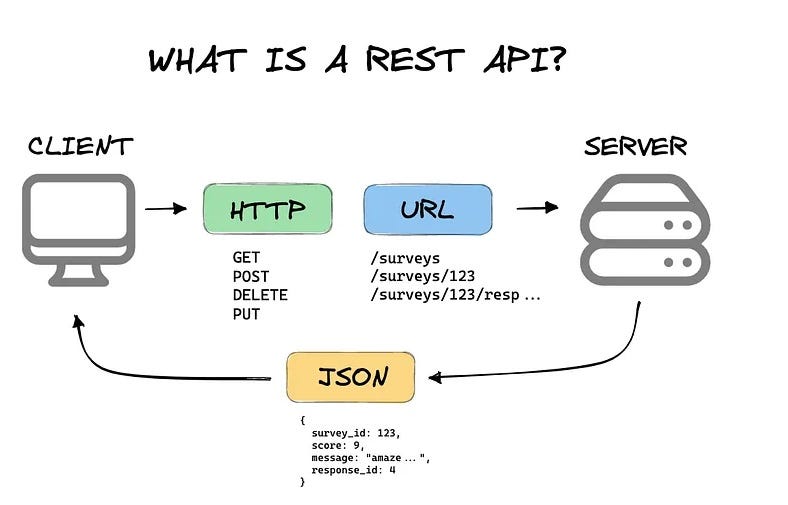
For years, backend developers have mastered the art of building robust, scalable, and predictable RESTful APIs. These APIs, built on the principles of resources, statelessness, and uniform interfaces, have powered the web and mobile applications we use daily. However, the dawn of the generative AI era is fundamentally challenging these established paradigms. Users no longer want to just fetch a resource by its ID; they want to have conversations, ask complex questions, and receive nuanced, context-aware answers. This shift demands a new kind of API—one that is intelligent, dynamic, and conversational.
This is where the latest Spring AI news is making significant waves across the Java landscape. Spring AI is an ambitious project from the Spring team designed to demystify the development of AI-powered applications. It provides a powerful abstraction layer over popular Large Language Models (LLMs) and AI infrastructure, allowing Java developers to integrate generative AI capabilities into their applications with the same ease and idiomatic style they expect from the Spring ecosystem. This article dives deep into how you can leverage Spring AI to design and build the next generation of APIs, moving beyond traditional REST to create truly intelligent backend services. We’ll explore core concepts, practical implementations, advanced techniques like Retrieval-Augmented Generation (RAG), and best practices for building production-ready AI APIs.
The Paradigm Shift: From RESTful to AI-Driven APIs
The core limitation of traditional REST in the AI era is its rigid, command-based nature. A REST API exposes a set of predefined endpoints that perform specific actions on specific resources. This works perfectly for structured UIs but falters when the user interaction is free-form, like a natural language query. An AI-powered application needs to understand intent, maintain context, and synthesize information from multiple sources—tasks that are cumbersome to orchestrate with a series of disconnected REST calls.
Introducing Spring AI: The Bridge to Modern LLMs
Spring AI acts as the essential bridge, translating the familiar Spring programming model into the world of generative AI. It abstracts away the complexities of interacting with different AI providers like OpenAI, Google Gemini, Ollama, and Hugging Face. The central component you’ll interact with is the ChatClient, a simple interface for sending prompts and receiving AI-generated responses.
This abstraction is a game-changer for the Java ecosystem news, as it allows developers to focus on application logic rather than boilerplate code for handling HTTP requests, retries, and parsing different AI provider response formats. Let’s see how simple it is to get a response from an AI model.
First, ensure your Spring Boot project (ideally using Java 17 news or Java 21 news for the latest features) includes the necessary dependencies:
<!-- pom.xml for Maven -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>0.8.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>After configuring your API key in application.properties (e.g., spring.ai.openai.api-key=YOUR_API_KEY), you can inject the ChatClient directly into your service.
import org.springframework.ai.chat.ChatClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class SimpleAiService {
private final ChatClient chatClient;
@Autowired
public SimpleAiService(ChatClient chatClient) {
this.chatClient = chatClient;
}
public String getSimpleResponse(String message) {
// The call() method is a synchronous, blocking call.
return chatClient.call(message);
}
}This simple service demonstrates the power of Spring AI. With just a few lines of code, you have a fully functional component capable of communicating with a powerful LLM, a significant piece of Spring news for developers looking to quickly prototype and build AI features.
Building Your First AI-Powered API Endpoint
With the service layer in place, exposing it via a web endpoint is standard practice for any developer familiar with Spring Boot. The goal is to create an API that accepts a natural language query and returns an AI-generated response, effectively acting as a proxy or orchestrator for the LLM.
Creating a Conversational Controller
Let’s create a RestController that exposes a POST endpoint. This endpoint will accept a simple JSON payload containing the user’s prompt and return the AI’s response.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Map;
@RestController
@RequestMapping("/api/v1/ai")
public class AiController {
private final SimpleAiService simpleAiService;
@Autowired
public AiController(SimpleAiService simpleAiService) {
this.simpleAiService = simpleAiService;
}
// A simple DTO for the request body
public record AiRequest(String prompt) {}
@PostMapping("/chat")
public Map<String, String> generateResponse(@RequestBody AiRequest request) {
String response = simpleAiService.getSimpleResponse(request.prompt());
return Map.of("response", response);
}
}This controller follows standard Spring MVC patterns, making it instantly familiar. However, the functionality it unlocks is far from standard. You now have an API that can answer questions, summarize text, write code, or perform any other task the underlying LLM is capable of. This is a foundational step, but the true power of designing APIs for AI comes from integrating your own data and business logic.
Advanced Techniques: RAG, Function Calling, and Structured Output
A simple proxy to an LLM is useful, but to build truly valuable AI applications, you need to ground the model with your specific domain data and grant it the ability to interact with other systems. This is where advanced techniques like Retrieval-Augmented Generation (RAG) and Function Calling come into play.
Retrieval-Augmented Generation (RAG) for Contextual APIs
RAG is a powerful technique that enhances LLM responses by providing them with relevant information retrieved from your own knowledge base. This prevents “hallucinations” and allows the AI to answer questions about private or recent data it wasn’t trained on. The latest Spring AI news includes robust support for the entire RAG pipeline.
The process involves:
- Loading Data: Ingesting documents (e.g., PDFs, Markdown files, database records).
- Splitting & Embedding: Breaking the documents into smaller chunks and converting them into numerical representations (embeddings) using a model.
- Storing: Storing these embeddings in a specialized Vector Database (e.g., Chroma, Weaviate, or PostgreSQL with pgvector).
- Retrieving: When a user asks a question, find the most relevant document chunks from the vector store.
- Augmenting: Add the retrieved context to the user’s prompt and send it to the LLM.
Spring AI provides abstractions for each of these steps. Here’s a conceptual example of how you might implement the retrieval and augmentation part in a service.
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@Service
public class RAGService {
private final ChatClient chatClient;
private final VectorStore vectorStore;
@Autowired
public RAGService(ChatClient chatClient, VectorStore vectorStore) {
this.chatClient = chatClient;
this.vectorStore = vectorStore;
}
public String queryWithContext(String userQuery) {
// 1. Retrieve relevant documents from the vector store
List<Document> relevantDocuments = vectorStore.similaritySearch(
SearchRequest.query(userQuery).withTopK(3)
);
String context = relevantDocuments.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n"));
// 2. Create a prompt template to augment the user query with context
String systemPromptText = """
You are a helpful assistant. Use the following information to answer the user's question.
If you don't know the answer, just say that you don't know.
CONTEXT:
{context}
""";
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemPromptText);
var prompt = systemPromptTemplate.create(Map.of("context", context));
// 3. Combine with user query and call the LLM
// Note: A full implementation would use a Prompt object with multiple messages.
String finalQuery = prompt.getContents() + "\n\nUSER QUESTION: " + userQuery;
return chatClient.call(finalQuery);
}
}This RAG pattern transforms your API from a general-purpose chatbot into a domain-specific expert, a crucial development in Java SE news for enterprise applications.

Function Calling for Tool Integration
Function Calling allows the LLM to go beyond just generating text. It can decide to invoke your application’s own functions to perform actions or retrieve real-time information. For example, an AI could call a function to get the current weather, check product inventory, or book a meeting. This makes your API an active participant in a workflow. The latest Project Loom news, with its introduction of virtual threads in modern Java versions, is particularly relevant here, as it simplifies handling the blocking I/O that often accompanies these function calls.
Spring AI supports this by allowing you to register Java Function beans that the LLM can invoke.
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.openai.OpenAiChatOptions;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Service;
import java.util.function.Function;
// Define the function the AI can call
@Configuration
class AppConfig {
@Bean
public Function<WeatherService.Request, WeatherService.Response> getCurrentWeather() {
return new WeatherService();
}
}
// A simple service representing our "tool"
class WeatherService implements Function<WeatherService.Request, WeatherService.Response> {
public record Request(String location) {}
public record Response(double temperature, String unit) {}
public Response apply(Request request) {
// In a real app, this would call an external weather API
return new Response(15.0, "Celsius");
}
}
@Service
class ToolCallingService {
private final ChatClient chatClient;
public ToolCallingService(ChatClient chatClient) {
this.chatClient = chatClient;
}
public String callWithTools(String prompt) {
var options = OpenAiChatOptions.builder()
.withFunction("getCurrentWeather") // Register the function by its bean name
.build();
// The AI model will see the function's signature and decide if it should call it
// Spring AI handles the invocation and response transparently.
return chatClient.call(new Prompt(prompt, options)).getResult().getOutput().getContent();
}
}When you ask the ToolCallingService, “What’s the weather in Paris?”, the LLM will recognize the intent, formulate a call to the getCurrentWeather function with the argument “Paris”, receive the result, and then generate a natural language response like, “The current weather in Paris is 15.0 degrees Celsius.”
Best Practices and Optimization
As you move from prototypes to production, several considerations become critical for building reliable, scalable, and cost-effective AI APIs.
API Design and Performance
- Streaming Responses: For long-running generative tasks, waiting for the full response leads to poor user experience. Use streaming APIs to send back tokens as they are generated. The Reactive Java news around Spring WebFlux and Project Reactor makes this particularly elegant to implement in the Java ecosystem.
- State Management: Conversations are stateful. You need a strategy to manage conversation history, whether it’s a simple in-memory cache for short sessions or a distributed cache like Redis for scalable, multi-node deployments.
- Prompt Engineering: Your prompt is your new API contract. Version your prompts, test them rigorously, and design them to be robust against ambiguity. This is as important as writing good unit tests with JUnit or Mockito.
- Cost and Latency: LLM calls can be slow and expensive. Implement aggressive caching for common queries, use smaller/faster models for simpler tasks, and employ circuit breakers to handle API failures from the AI provider. Good Java performance news is that the modern JVM is highly optimized, but external network calls remain a bottleneck.
Security and Observability
The Java security news landscape is evolving with AI. A major new threat is Prompt Injection, where a malicious user crafts input to hijack the AI’s instructions. Always treat input from users as untrusted and use techniques like instruction-fencing in your prompts to mitigate this risk.
Furthermore, observability is key. Log your prompts, the generated responses, token counts, and latency. This data is invaluable for debugging, monitoring costs, and identifying areas for improvement in your AI-driven system.
Conclusion
The rise of generative AI is not just another trend; it’s a fundamental shift in how we build and interact with software. As backend developers, our role is evolving from crafting rigid, resource-based APIs to orchestrating intelligent, conversational, and context-aware services. The latest Spring Boot news and the emergence of frameworks like Spring AI and LangChain4j have positioned the Java ecosystem at the forefront of this transformation.
By embracing abstractions like ChatClient, implementing advanced patterns like RAG and Function Calling, and adhering to best practices around performance and security, you can build powerful next-generation APIs. The journey starts with a simple endpoint but leads to a future where your backend services are not just data providers but intelligent partners in a conversation. The tools are here, the patterns are emerging, and now is the perfect time to start building the future of APIs with Spring AI.